Eicky BlogMy Awesome Blog Site2019-11-04T06:37:03.646Zhttps://eicky.com/EickyHexo让aws、gcp、oracle等机器使用root账户登录https://eicky.com/2019/11/04/linux/2019-11-03T16:00:00.000Z2019-11-04T06:37:03.646Z
[toc]
让aws、gcp、oracle等机器使用root账户登录
先使用能登录的方式登录上vps
切换到root
sudo -i
修改root密码(如果不用密码登录使用public_key方式登录,这一步可以跳过)
1 2 3 4 5
sudo passwd root Enter new UNIX password:#输入自己设置的新密码 Retype new UNIX password:#再次输入
更改登录方式
1 2 3 4 5 6 7 8
#开启PasswordAuthentication 和 PermitRootLogin vim /etc/ssh/sshd_config #将下面两个值设置成yes,如果注释了把注释取消掉 PasswordAuthentication yes PermitRootLogin yes
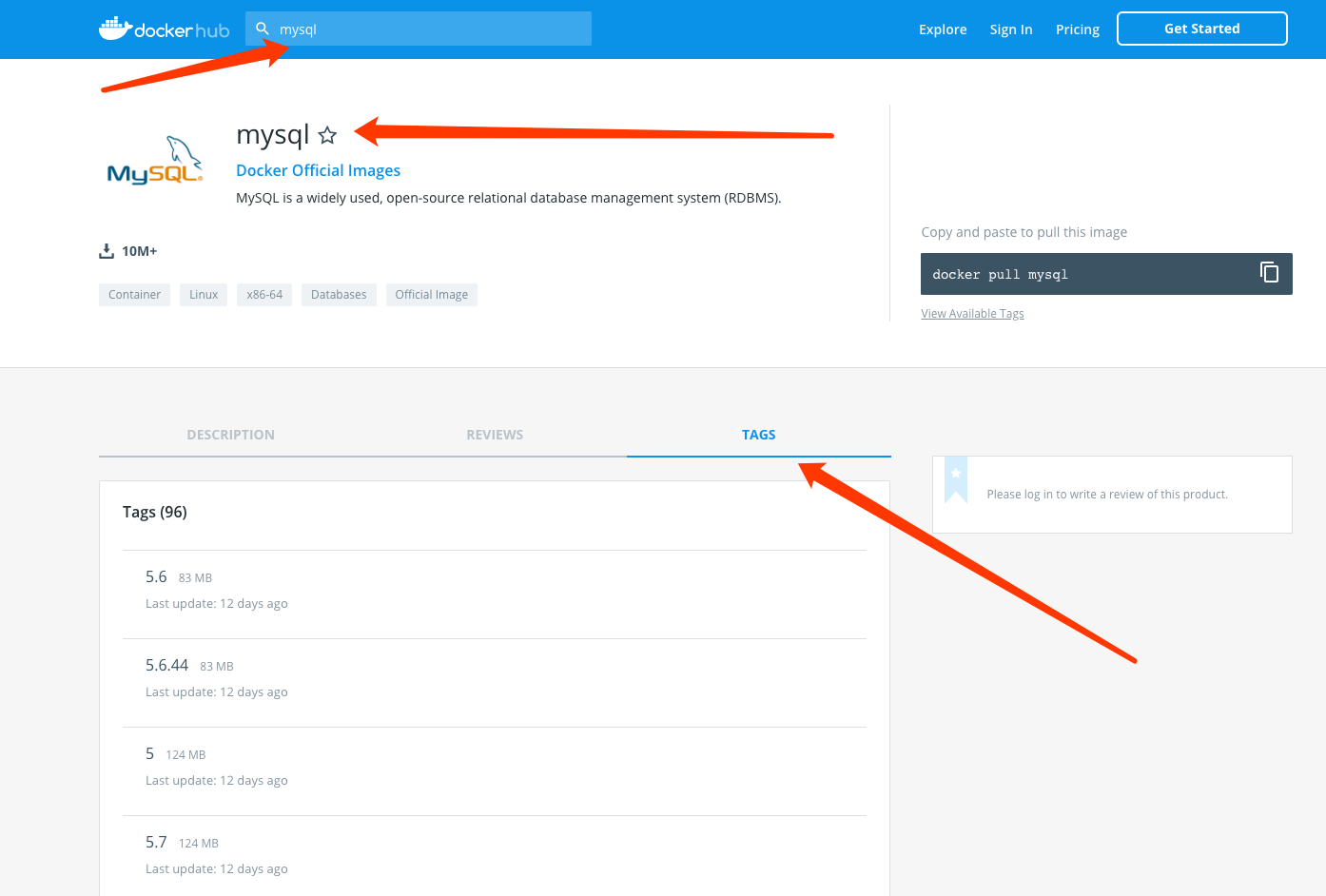
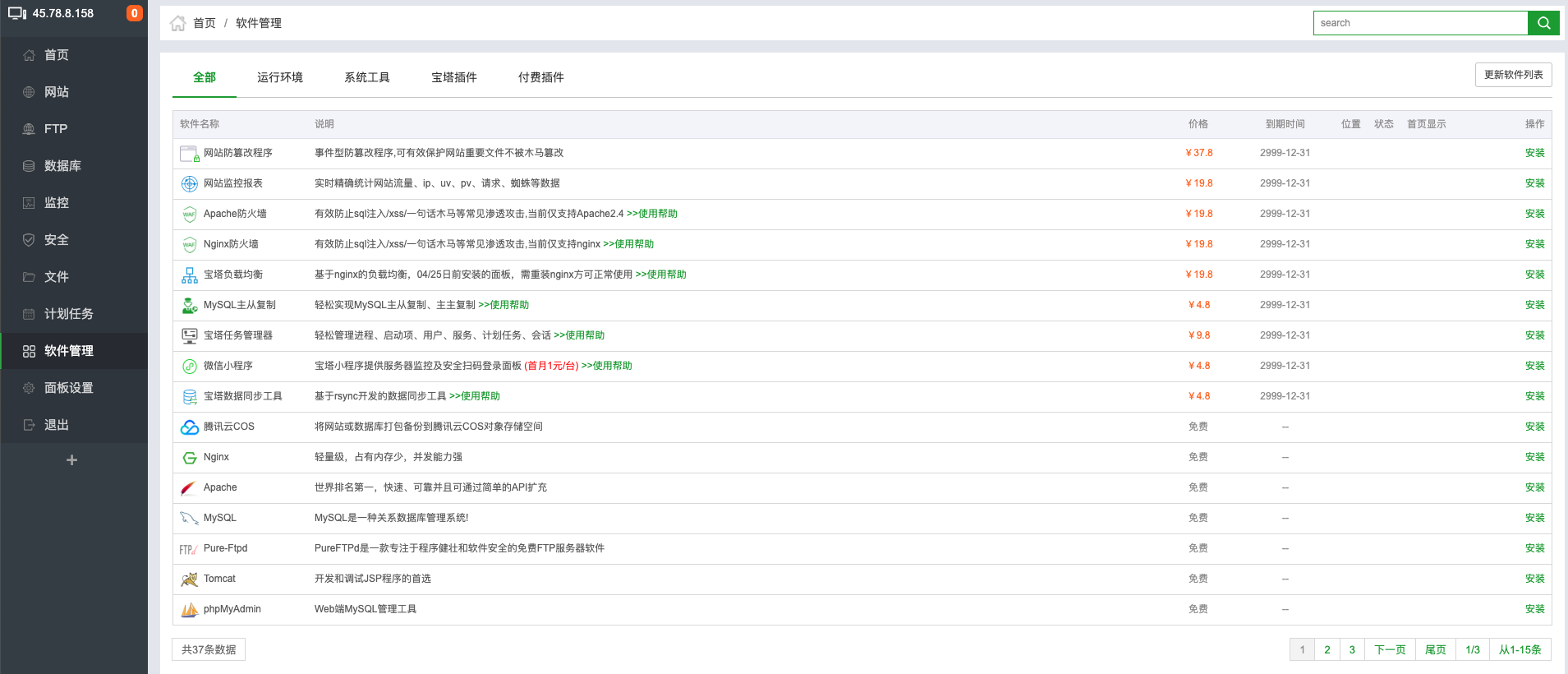
docker run --name container-name -d image-name 其中--name是你为容器取的名称供你自己以后查看;-d表示detached,意思执行玩这句命令后控制台将不会被阻碍,可以继续输入命令操作, image-name是你要使用的哪个镜像(当然你得先下载下来,pull命令) eg: docker run --name mysql-test -d mysql
查看运行中的容器列表
1 2
docker ps docker ps -a (注:这个命令是用来查看所有容器的,也就是运行和停止状态的都展示出来,类似ls -a?)
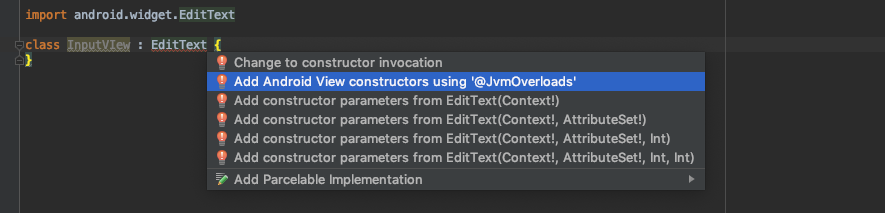
/** * Instructs the Kotlin compiler to generate overloads for this function that substitute default parameter values. * * If a method has N parameters and M of which have default values, M overloads are generated: the first one * takes N-1 parameters (all but the last one that takes a default value), the second takes N-2 parameters, and so on. */ @Target(AnnotationTarget.FUNCTION, AnnotationTarget.CONSTRUCTOR) @Retention(AnnotationRetention.BINARY) @MustBeDocumented public annotation classJvmOverloads
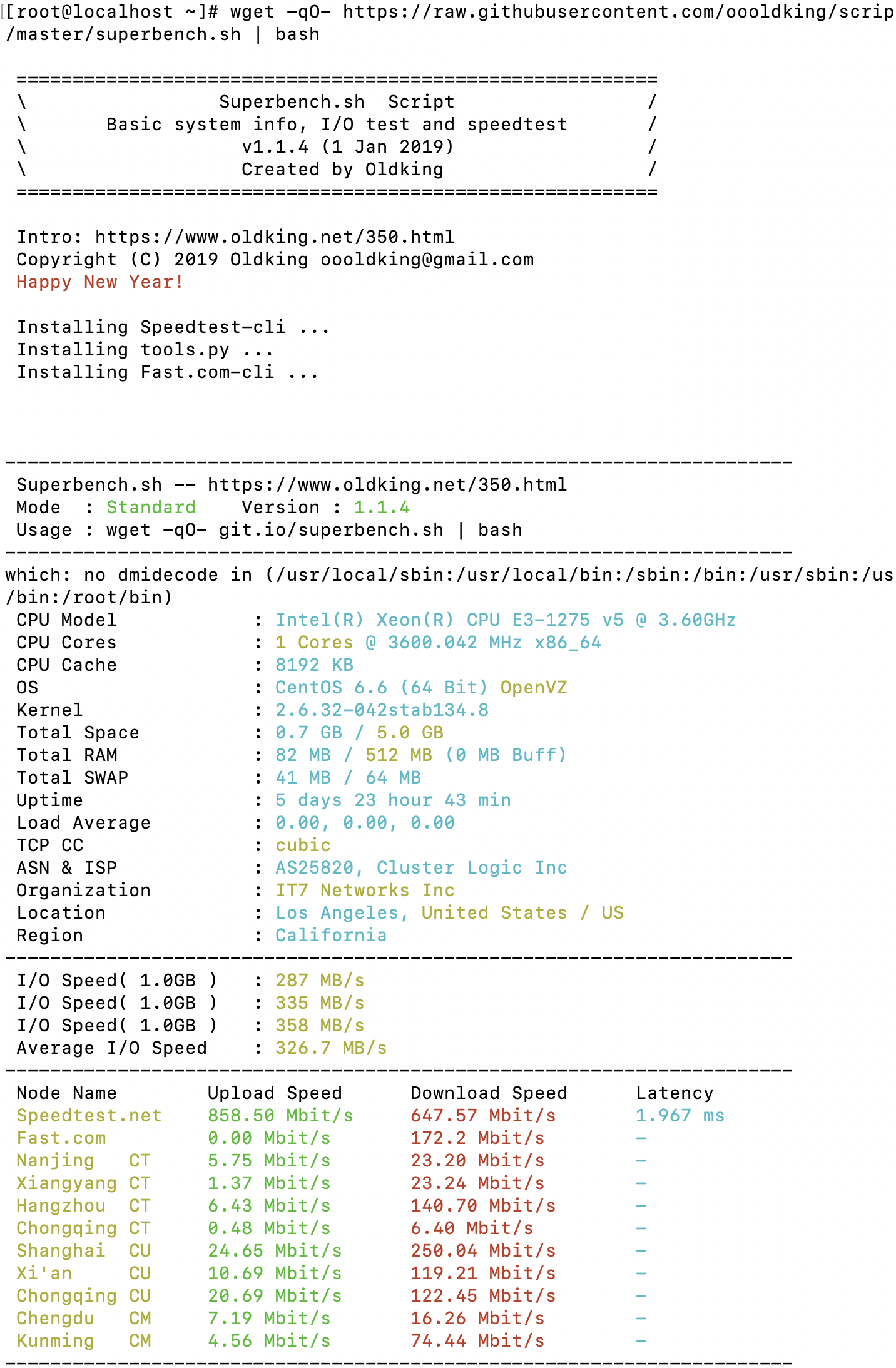
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256m; support was removed in 8.0
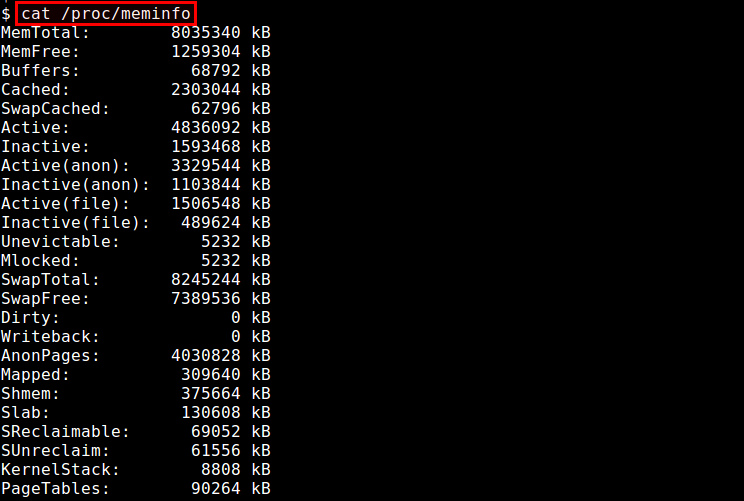
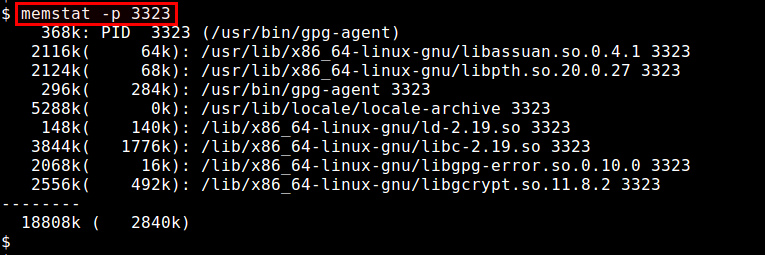
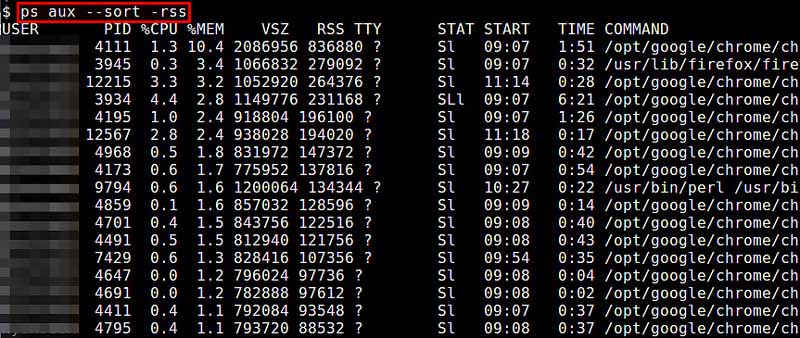
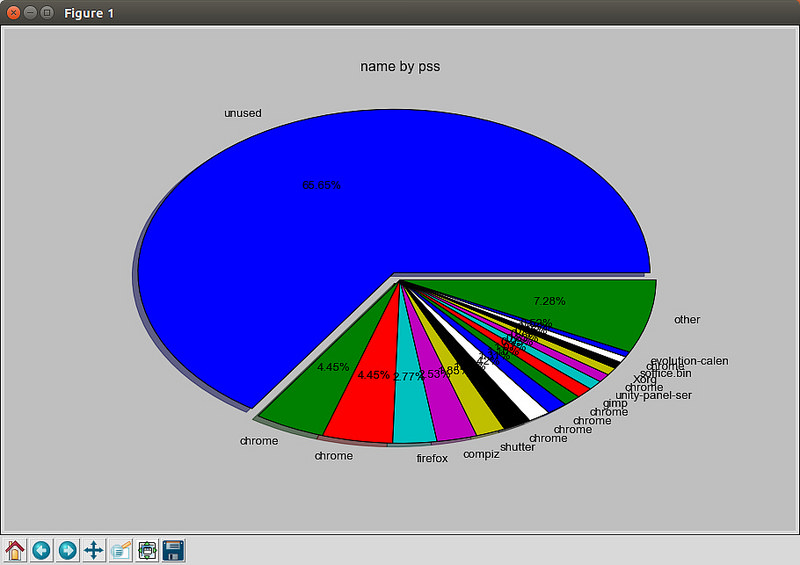
ps命令可以实时的显示各个进程的内存使用情况。Reported memory usage information includes %MEM (percent of physical memory used), VSZ (total amount of virtual memory used), and RSS (total amount of physical memory used)。你可以使用 “–sort”选项对进程进行排序,例如按RSS进行排序:
]]>
<script src="/assets/js/APlayer.min.js"> </script><hr>
<p>[toc]</p>
<hr>
<p>国内国外免费接收短信验证码:国外14个网站国内1个网站 分享一些国内国外的短信验证码接收网站,注册某些网站的时候可以临时用一下,
Mac 上 Class JavaLaunchHelper is implemented in both 报错https://eicky.com/2019/01/17/java/2019-01-16T16:00:00.000Z2019-07-12T09:47:54.735Z
[toc]
Class JavaLaunchHelper is implemented in both /Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home/bin/java (0x10d19c4c0) and /Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home/jre/lib/libinstrument.dylib (0x10ea194e0). One of the two will be used. Which one is undefined.
IDEA-170117 “objc: Class JavaLaunchHelper is implemented in both …” warning in Run consoles
It’s the old bug in Java on Mac that got triggered by the Java Agent being used by the IDE when starting the app. This message is harmless and is safe to ignore. Oracle developer’s comment:
The message is benign, there is no negative impact from this problem since both copies of that class are identical (compiled from the exact same source). It is purely a cosmetic issue.
If it annoys you or affects your apps in any way, the workaround for IntelliJ IDEA is to disable idea_rt launcher agent by adding idea.no.launcher=true into idea.properties (Help | Edit Custom Properties…).
]]>
<script src="/assets/js/APlayer.min.js"> </script><hr>
<p>[toc]</p>
<hr>
<p>Class JavaLaunchHelper is implemented in both /Library/Java/Java
常用vi编辑器命令https://eicky.com/2019/01/15/linux/2019-01-14T16:00:00.000Z2021-06-29T03:22:35.391Z
<divid="player1"class="aplayer"></div> <scriptsrc="/js/src/APlayer.min.js"></script> <scripttype="text/javascript"> var ap = new APlayer({ element: document.getElementById('player1'), // Optional, player element narrow: false, // Optional, narrow style autoplay: false, // Optional, autoplay song(s), not supported by mobile browsers showlrc: 0, // Optional, show lrc, can be 0, 1, 2, see: ###With lrc mutex: true, // Optional, pause other players when this player playing theme: '#e6d0b2', // Optional, theme color, default: #b7daff mode: 'random', // Optional, play mode, can be `random` `single` `circulation`(loop) `order`(no loop), default: `circulation` preload: 'metadata', // Optional, the way to load music, can be 'none' 'metadata' 'auto', default: 'auto' listmaxheight: '513px', // Optional, max height of play list music: { // Required, music info, see: ###With playlist title: '你曾是少年', // Required, music title author: 'cover', // Required, music author url: 'http://mp3.qqmusic.cc/yq/102426570.mp3', // Required, music url pic: '/images/visitor.jpg', // Optional, music picture } }); </script>
template<typename T> voidMergeSortIteration(T *array, constint length){ if (array == NULL) throw invalid_argument("Array must not be empty"); if (length <= 0) return;
T* regB = (T*)malloc(sizeof(T) * length);
if (regB == NULL) { fputs("Error: out of memory\n", stderr); abort(); } for (int seg = 1; seg < length; seg += seg) {//步长,每次翻倍 for (int left = 0; left < length; left += seg + seg) { int low = left, mid = min(left + seg, length), high = min(left + seg + seg, length);//因为可能会超出length int k = low; int left1 = low, right1 = mid; int left2 = mid, right2 = high; while (left1 < right1 && left2 < right2)//这里的表达式没有等号,都是左闭右开区间 regB[k++] = array[left1] < array[left2] ? array[left1++] : array[left2++]; while (left1 < right1) regB[k++] = array[left1++]; while (left2 < right2) regB[k++] = array[left2++]; } for (int i = 0; i < length; i++)//更新array array[i] = regB[i]; } delete[] regB; }
template<typename T> voidMergeSortIteration1(T *array, constint length){ if (array == NULL) throw invalid_argument("Array must not be empty"); if (length <= 0) return;
template <typename T> void QuickSort(T *array, const int length) { if (array == NULL) throw invalid_argument("Array must not be empty"); if (length <= 0) return;
template <typename T> voidPartion1(T *array, int left, int right){ if (left >= right) return;
int i = left; int j = left + 1; T pivot = array[left];// 取第一个数为基准 for (; j <= right; ++j){// 循环直至 j 扫描至 right if (array[j] < pivot){// 如果遇到比基准小的数,i右移一位 i++; if (j != i){// 如果i与j不重合,则交换他们指向的值 swap(array[j],array[i]); } } } swap(array[left], array[i]);// 基准值的位置确定 Partion1(array, left, i - 1); Partion1(array, i + 1, right); }
template <typename T> voidPartion2(T *array, int left, int right){ if (left >= right) return;
int i = left + 1; int j = right; T pivot = array[left];// 取第一个数为基准 while (i < j){// 循环直至 i,j 相遇 while (i < j && array[j] >= pivot)// j向左遍历,直到找到比pivot小的值 --j; while (i < j && array[i] < pivot)// i向右遍历,直到找到比pivot大的值 ++i; if (i < j)// 如果i < j,就交换刚才找到的那两个值 swap(array[j], array[i]); }
if (array[i] <= array[left])// 这里一定要做判断再决定是否交换 swap(array[i], array[left]);
else// 如果不交换,说明left是最小,但i是不是第二小不确定,所以需要下次判断 --i; Partion2(array, left, i - 1); Partion2(array, i + 1, right); }
template <typename T> voidPartion3(T *array, int left, int right){ if (left >= right) return;
int i = left; int j = right; T pivot = array[left];// 取第一个数为基准 while (i < j){// 循环直至 i,j 相遇 while (i < j && array[j] >= pivot) --j; if (i < j) array[i++] = array[j];// 从右向左扫描,将比基准小的数填到左边 while (i < j && array[i] < pivot) ++i; if (i < j) array[j--] = array[i];// 从左向右扫描,将比基准大的数填到右边 } array[i] = pivot;// 将基准数填回 Partion3(array, left, i - 1); Partion3(array, i + 1, right); }
while (!trace.empty()) { auto top = trace.top();// 将栈顶元素保存下来 trace.pop();// 弹出栈顶
int i = top.first;// 取出首尾地址 int j = top.second;
T pivot = array[i];// 取第一个数为基准
while (i < j) {// 循环直至 i,j 相遇 while (i < j && array[j] >= pivot) --j; if (i < j) array[i++] = array[j];// 从右向左扫描,将比基准小的数填到左边 while (i < j && array[i] < pivot) ++i; if (i < j) array[j--] = array[i];// 从左向右扫描,将比基准大的数填到右边 }
array[i] = pivot;// 将基准数填回
if (i > top.first) trace.push(make_pair(top.first, i - 1)); if (j < top.second) trace.push(make_pair(j + 1, top.second)); } }
template <typename T> voidPartionInsert(T *array, int left, int right){ if (left >= right) return;
if (right - left <= M) InsertSort(array, left, right); else{ int i = left; int j = right; T pivot = array[left];// 取第一个数为基准 while (i < j){// 循环直至 i,j 相遇 while (i < j && array[j] >= pivot) --j; if (i < j) array[i++] = array[j];// 从右向左扫描,将比基准小的数填到左边 while (i < j && array[i] < pivot) ++i; if (i < j) array[j--] = array[i];// 从左向右扫描,将比基准大的数填到右边 } array[i] = pivot;// 将基准数填回 PartionInsert(array, left, i - 1); PartionInsert(array, i + 1, right); } }
//产生随机数 template <typename T> voidRandom(T *array, int left, int right) { int size = right - left + 1; int i = left + rand() % size; swap(array[i], array[left]); }
//取中位数移至left template <typename T> voidMedian(T *array, int left, int right) { int mid = left + ((right - left )>> 1); int minIndex = right;
if (array[minIndex] > array[mid]) minIndex = mid; if (array[minIndex] > array[left]) minIndex = left; if (minIndex != right)//三个判断,把最小值移到最右侧 swap(array[minIndex], array[right]); if (array[mid] < array[left])//那么剩下的两个数,最小的那个就是中位数了 swap(array[left], array[mid]); }
/* * 快速排序3优化2: * 取随机数或者三值取中作为基准值 */
template <typename T> voidPartionSecond(T *array, int left, int right){ if (left >= right) return;
//Random(array, left, right);// 优化2-1:取随机数至最左端(基准值) Median(array, left, right);// 优化2-2:取中位数至最左端(基准值) int i = left; int j = right; T pivot = array[left];// 取第一个数为基准 while (i < j){// 循环直至 i,j 相遇 while (i < j && array[j] >= pivot) --j; if (i < j) array[i++] = array[j];// 从右向左扫描,将比基准小的数填到左边 while (i < j && array[i] < pivot) ++i; if (i < j) array[j--] = array[i];// 从左向右扫描,将比基准大的数填到右边 } array[i] = pivot;// 将基准数填回 PartionSecond(array, left, i - 1); PartionSecond(array, i + 1, right); }
/* * 快速排序3优化3: * 重复数据比较多的话,可以分为小于等于大于三段 */
template <typename T> voidPartionThird(T *array, int left, int right){ if (left >= right) return;
int less = left; int greater = right; int it = left; T pivot = array[left];// 取第一个数为基准 while (it <= greater){// 循环直至it和greater相遇 if (array[it] == pivot)// 如果等于pivot,it右移 ++it; elseif (array[it] < pivot){// 如果小于pivot,扔左边,it和less右移 swap(array[less], array[it]); ++it; ++less; } else{// 如果大于pivot,扔右边,greater左移 swap(array[greater], array[it]); --greater; } } PartionThird(array, left, less - 1); PartionThird(array, greater + 1, right); }
template <typename T> voidBubbleSort(T *array, constint length){ if (array == NULL) throw invalid_argument("Array must not be empty"); if (length <= 0) return;
for (int i = 0; i < length - 1; ++i){//外循环,每次循环确定一个最大值 for (int j = 0; j < length - 1 - i; ++j){//内循环,用于交换数据,遍历次数递减 if (array[j] > array[j + 1]){//如果当前数据比后面的数据大,则交换 T tmp = array[j + 1]; array[j + 1] = array[j]; array[j] = tmp; } } } }
template <typename T> voidBubbleSort2(T *array, constint length){ if (array == NULL) throw invalid_argument("Array must not be empty"); if (length <= 0) return; int k = length; int flag = k;//设置标志位,用来判断内循环是否有数据交换 for (int i = 0; i < length - 1; ++i){//外循环,每次循环确定一个最大值 k = flag; flag = 0;//外循环第一步需要重置标志位 for (int j = 0; j < k - 1; ++j){//内循环,用于交换数据,遍历次数递减 if (array[j] > array[j + 1]){//如果当前数据比后面的数据大,则交换 T tmp = array[j + 1]; array[j + 1] = array[j]; array[j] = tmp; flag = j + 1;//如果有交换,更新交换位置的记录 } } if (!flag) return;//如果本次循环没有数据交换,则结束排序 } }
template <typename T> voidBubbleSort3(T *array, constint length){ if (array == NULL) throw invalid_argument("Array must not be empty"); if (length <= 0) return; int low = 0; int high = length - 1;
while (high > low) { for (int i = low; i < high; ++i)//正向冒泡,确定最大值 { if (array[i] > array[i + 1]) { T temp = array[i]; array[i] = array[i + 1]; array[i + 1] = temp; } } --high;